Securiser son deploiement Terraform sur AWS via Gitlab-CI et Vault (pipeline side)
Nous avons vu dans les précédents articles comment utiliser l’outil Hashicorp Vault pour la centralisation des secrets statiques, dynamiques ou encore pour l’Encryption as a Service. Dans cet articles nous irons plus loin et verrons comment sécuriser son déploiement Terraform sur AWS au travers de Gitlab-CI et de l’aide de Vault. Cet article sera consacré à l’utilisation des secrets au niveau de notre CI.
Prérequis
Précision : au moment d’écrire cet article, Vault est en version 1.6.3.
Autre précision: Nous nous basons sur la version gratuite de gitlab.com et Gitlab Community Edition (CE).
Prérequis :
- Vault: mécaniques de bases telles que l’authentification et les types de secrets.
- AWS: IAM (rôle, assume rôle, etc) et EC2 (metadata, instance profile, etc) seront vus mais ne nécessitent pas un niveau avancé. Il est toutefois préférable d’avoir une base de connaissances sur AWS.
- Gitlab-CI: les fondamentaux sur la partie CI de Gitlab (gitlab-ci.yml, pipeline, etc).
- Terraform: les fondamentaux seront suffisants.
Enfin, cet article fait suite à l’article Réduire sa dépendance code avec Vault Agent.
Le challenge de notre CI ?
La CI/CD est couramment employée dans les déploiements d’Infrastructure as Code (IaC) et d’applications sur les plateformes Cloud. Ces plateformes offrent une flexibilité de déploiement au travers de leurs API.
Cependant, comment donner accès à notre CI sur ces environnements de façon sécurisée ?
Dans cet article nous nous concentrerons, d’une part, sur Gitlab-CI pour notre CI et Terraform pour l’IaC, afin d’être agnostique par rapport à l’environnement.
D’autre part, AWS est pris comme exemple mais nous pouvons appliquer cette logique à n’importe quel autre cloud provider.
Une CI externe à AWS, un facteur de complexité
AWS a une bonne intégration entre ses services notamment quand nous restons dans son écosystème.
Il est par contre plus compliqué d’utiliser une CI externe à AWS, Gitlab-CI dans notre cas, qui a besoin d’utiliser AWS pour déployer/configurer des services.
Prenons pour exemple le scénario suivant :
Nous avons une application sur une instance EC2 contenant un serveur web qui utilise une base de données MySQL sur RDS. Nous souhaitons déployer cette infrastructure sous forme d’IaC avec Terraform en utilisant Gitlab-CI.
Ce qui nous donne le workflow suivant :
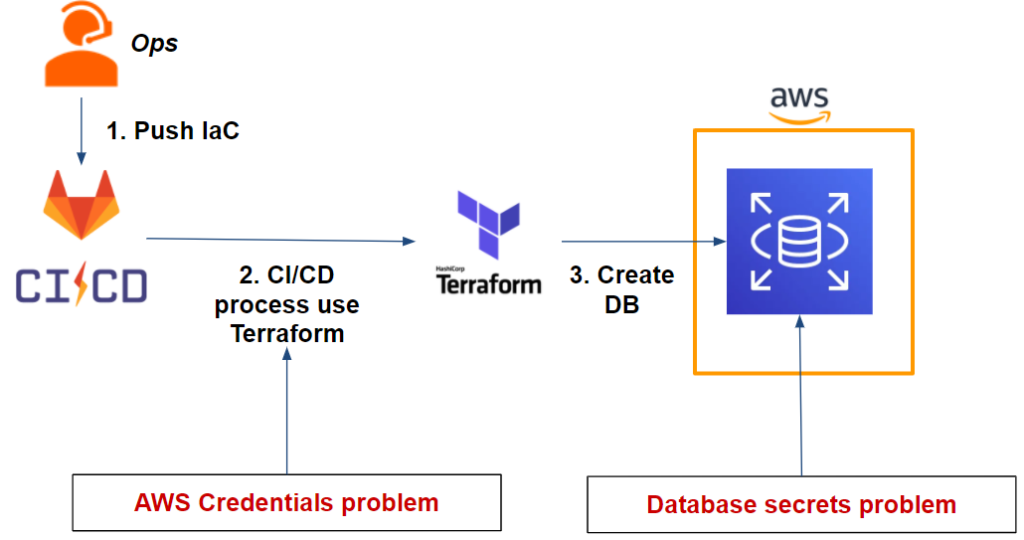
Comme nous pouvons le voir sur notre workflow, nous avons deux problématiques:
- Notre pipeline Gitlab-CI: Terraform a besoin des credentials AWS pour être en capacité de déployer la base de données RDS sur AWS.
- La base de données: Nous devons stocker de façon sécurisée les credentials de l’utilisateur admin qui seront générés une fois la base de données déployée.
Essayer de résoudre le challenge en pensant AWS
Concentrons-nous sur notre première problématique concernant notre pipeline Gitlab-CI et nos credentials AWS. Comment pouvons-nous résoudre ce problème ?
Première tentative: l’utilisateur IAM et les variables d’environnement
La méthode la plus simple et rapide pour résoudre ce problème est de créer un utilisateur IAM et de générer un couple d’ACCESS KEY et SECRET KEY qu’on mettra en variable d’environnement de notre projet.
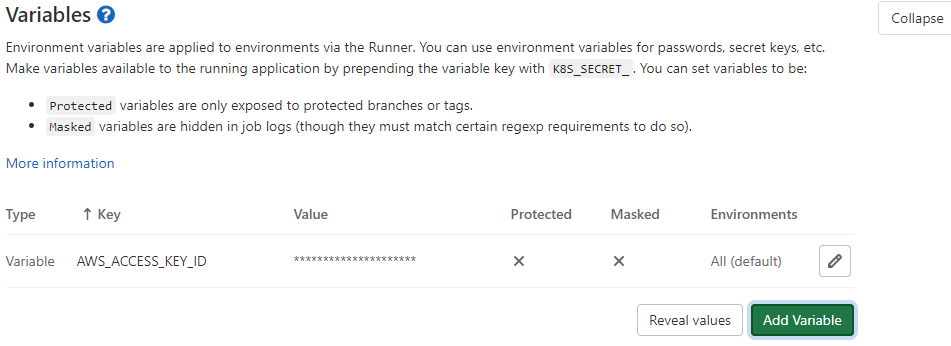
De cette manière, notre Terraform sera en capacité de déployer l’infrastructure applicative sur AWS et en particulier notre RDS. Ceci est possible car Terraform est en capacité de récupérer les credentials AWS via les variables d’environnement.
En effet, cette méthode est la plus simple et rapide pour résoudre le problème cité plus haut mais soulève plusieurs questions:
- Les credentials sont statiques, il faut donc mettre en place un système de rotation.
- Par corollaire, le système devra avoir des accès entre Gitlab-CI et AWS pour faire cette rotation, ce qui entraîne donc d’autres questions autour des accès/credentials
- Il est difficile d’avoir et de mettre en place des credentials pour chaque environnement et isoler par branche GIT (ex: master, dev, features/*)
- Une personne ayant les permissions au moins Maintainer ou Owner d’un projet est en capacité de voir/modifier les variables de la CI/CD. Ainsi, certains utilisateurs ayant un droit fort sur Gitlab mais n’étant pas forcément légitimes à obtenir ces secrets applicatifs ou CI seront en capacité de les récupérer ou même de les modifier.
- En allant plus loin dans l’idée, un utilisateur en capacité de récupérer un secret sans contrainte de vérification de sa source (ex: filtrage sur l’IP source, etc) pourra l’utiliser en dehors de la CI. Cela entraîne l’impossibilité d’identifier l’utilisateur réel de ce secret ou même sa légitimité.
Cette situation peut nous amener rapidement à perdre le contrôle de l’accès et de l’usage du secret :
Deuxième tentative: utilisation d’un rôle IAM et/ou instance profile AWS
Une deuxième option est envisageable si votre Gitlab Runner se situe sur AWS.
En repartant sur notre première hypothèse, nous pouvons supprimer notre utilisateur IAM ainsi que ses credentials côté Gitlab CI/CD variables et créer un rôle IAM.
L’objectif est, pour notre Gitlab Runner, d’assumer le rôle IAM en question afin de bénéficier de credentials temporaires.
Si notre Gitlab Runner est sur une instance EC2, il suffit de mettre une instance profile :

Si celui-ci est sur un AWS ECS (Elastic Container Service), il faudra attribuer un rôle IAM à notre container.
Il est aussi possible de faire la même chose avec EKS (Elastic Kubernetes Service).
Les problématiques soulevées dans la tentative précédente sont résolues cependant :
- Les credentials s’appliquent au niveau du Gitlab Runner. Ce qui signifie que tous les projets Gitlab-CI qui ont accès à ce container/Gitlab Runner bénéficieront des mêmes privilèges IAM. Or, nous cherchons à avoir du least privilege pour chaque projet.
- Même si nous cherchons à faire un Gitlab Runner par projet, il est difficile d’isoler les privilèges du Gitlab Runner pour chaque environnement ou par branche GIT (ex: master, dev, features/*)
- Cette solution est uniquement utilisable si nous prenons en considération la possibilité de pouvoir déployer notre Gitlab Runner sur AWS (ce qui n’est pas le cas pour tous).
Comme nous pouvons le voir suite à ce deuxième essai, le réel challenge n’est pas de donner accès à AWS à notre Gitlab Runner ou encore à notre projet mais plutôt à notre pipeline/Gitlab-CI pour un environnement précis avec une mécanique de least privilege (notamment dans une optique de cloud agnostique).
De plus, nous n’avons pas encore abordé la problématique des secrets de la base de données.
Vault, la solution à notre challenge
comme nous l’avons vu, il est difficile d’authentifier un pipeline ou même un job Gitlab-CI afin de permettre l’accès à nos secrets en least privilege de façon sécurisée. HashiCorp Vault nous permet de répondre à ce besoin de façon uniformisée et cloud agnostique.
Penchons nous de nouveau sur notre workflow en ajoutant cette fois-ci Vault:
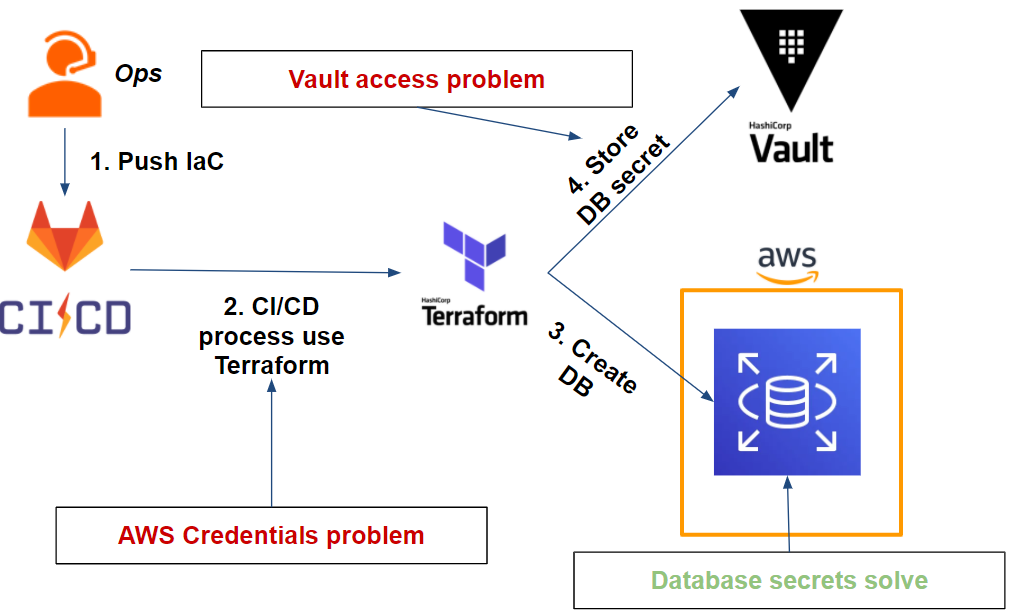
Dans un premier temps, Vault nous permet de stocker nos secrets de base de données et de s’occuper de la rotation. Nous aborderons ce point plus en détail dans la suite de notre article.
Dans un second temps, il est possible pour Vault de générer des credentials AWS et de façon dynamique. Cependant, il soulève une nouvelle problématique qui est commune à notre précédente question : comment pouvons-nous autoriser un job Gitlab-CI à utiliser et stocker des secrets dans Vault ?
Afin de résoudre cette problématique avec Vault, nous allons adresser 3 points que nous allons résoudre au fur et à mesure:
- Vault doit générer des secrets AWS dynamiquement: au travers du secret engine AWS, nous verrons comment Vault peut générer des credentials a least privilege sur plusieurs comptes AWS cibles différents.
- Notre pipeline (Gitlab-CI) doit, sur une branche précise, s’authentifier auprès de Vault: au travers de la méthode d’authentification de type JWT, il est possible d’authentifier notre pipeline sur une branche précise avec Vault.
- Notre pipeline doit pouvoir utiliser et stocker des secrets dans Vault: Notre pipeline devra, une fois authentifié a Vault, récupérer ses secrets de type AWS et stocker les secrets de base de données.
Pour ce faire, nous utiliserons Terraform afin de configurer notre Vault via le provider Vault.
L’ensemble du code sur lequel s’appuie cet article pour la démonstration peut se retrouver sur ce repository GitHub.
Génération des secrets dynamiques avec Vault
Notre premier objectif est de faire en sorte que notre Vault soit en capacité de générer des secrets AWS dynamiques avec least privilege.
Vault utilise le secret engine AWS qui est en capacité de générer 3 type de credentials AWS :
- IAM user : Vault crée un un utilisateur IAM et génère puis retourne ses accès programmatiques (access key et secret key).
- Assumed role : Vault va assumer un role IAM et retourner les credentials de la session (access key, secret key et session token).
- Federation token : les credentials retournés sont les mêmes que l’assume role IAM mais cette fois-ci pour un utilisateur fédéré.
Parmi les 3 méthodes, nous verrons celle de l’assume role IAM qui sera notamment utile dans notre cadre de multi-comptes AWS.
Prenons l’exemple suivant : nous avons plusieurs comptes AWS cibles sur lesquels Vault doit être en mesure de générer des credentials AWS via un assume rôle IAM. Cela donnera le scénario suivant :
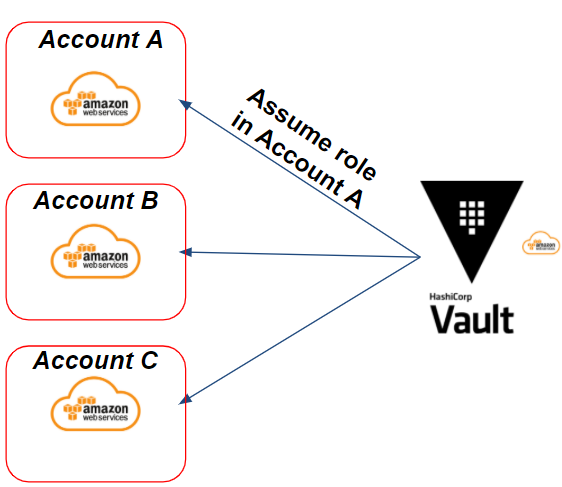
Dans notre exemple, nous avons besoin de générer des credentials sur le compte AWS A cible. Vault va assumer un rôle IAM sur le compte A ciblé afin de générer des credentials AWS dynamiques.
Préparation des rôles IAM côté AWS
Pour ce faire, Vault doit avoir des credentials AWS et des permissions pour être en capacité de faire ses actions sur AWS.
Concernant les credentials, nous avons 2 cas de figures:
- Si Vault est dans un environnement AWS et sur une instance EC2/ECS : nous pouvons utiliser les instances profiles afin d’utiliser des credentials AWS temporaires.
- Si Vault est en dehors d’un environnement AWS : il nous faudra générer Access Key et Secret Key via un utilisateur IAM et faire une rotation régulière de ses credentials.
Concernant les permissions, HashiCorp prend comme exemple la policy suivante :
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iam:AttachUserPolicy",
"iam:CreateAccessKey",
"iam:CreateUser",
"iam:DeleteAccessKey",
"iam:DeleteUser",
"iam:DeleteUserPolicy",
"iam:DetachUserPolicy",
"iam:ListAccessKeys",
"iam:ListAttachedUserPolicies",
"iam:ListGroupsForUser",
"iam:ListUserPolicies",
"iam:PutUserPolicy",
"iam:AddUserToGroup",
"iam:RemoveUserFromGroup"
],
"Resource": ["arn:aws:iam::ACCOUNT-ID-WITHOUT-HYPHENS:user/vault-*"]
}
]
}
Cet exemple est utile si nous voulons que Vault génère des utilisateurs IAM. Cependant, ce type de policy donne beaucoup trop de droits par rapport à notre besoin d’assumer un role.
La policy suivante est nécessaire pour répondre à notre besoin :
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "*"
}
}
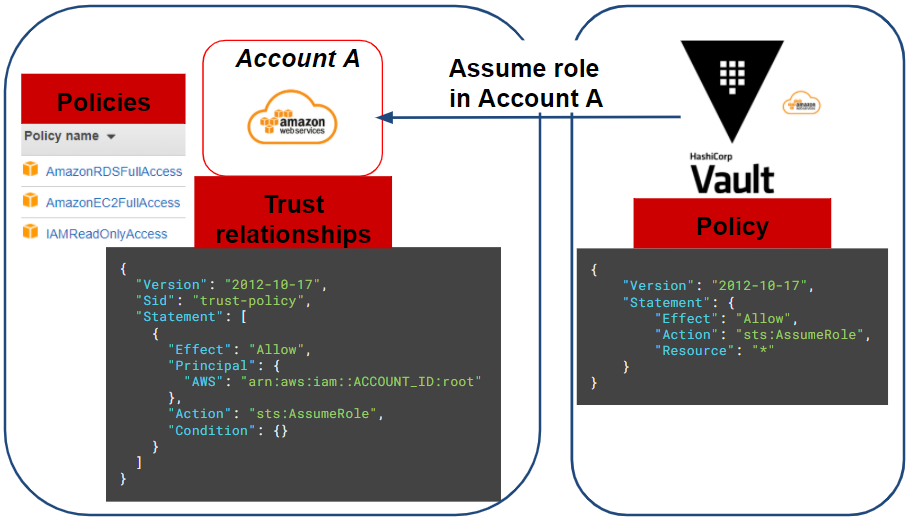
Une fois que Vault a ses accès programmatiques au compte source AWS et les permissions nécessaires, il ne nous reste plus qu’à créer le rôle IAM (ou les rôles IAM si nous avons plusieurs comptes AWS cible) que Vault doit assumer.
Pour notre scénario, nous aurons besoin de déployer une instance EC2 et une base de données de type RDS. Nous allons utiliser les policies (AWS managed) suivantes sur le rôle IAM sur notre compte AWS cible (account A):
- AmazonRDSFullAccess
- AmazonEC2FullAccess
- IAMReadOnlyAccess
Cette policy sera limitée plus tard au travers de notre Vault pour notre application.
Enfin, le rôle IAM du compte cible doit avoir une trust relationships pour autoriser Vault à assumer celui-ci :
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::ACCOUNT_ID:root"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}
Pour résumer l’ensemble de nos actions, le schéma suivant représente notre situation actuelle :
Configuration du rôle Vault
Maintenant que nous avons configuré la partie AWS, il ne reste plus qu’à configurer notre Vault via Terraform :
resource "vault_aws_secret_backend" "aws" {
description = "AWS secret engine for Gitlab-CI pipeline"
path = "${var.project_name}-aws"
region = var.region
}
resource "vault_aws_secret_backend_role" "pipeline" {
backend = vault_aws_secret_backend.aws.path
name = "${var.project_name}-pipeline"
credential_type = "assumed_role"
role_arns = [var.application_aws_assume_role]
policy_document = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:*",
"rds:*"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"iam:GetUser"
],
"Resource": "arn:aws:iam::*:user/$${aws:username}"
}
]
}
EOF
}
Ici nous créons notre secret engine de type AWS et un rôle Vault qui assumera le rôle IAM créé au préalable sur le compte AWS cible.
On remarque, dans la policy document du rôle Vault, que nous pouvons restreindre les droits de notre session AWS (credential) au travers de Vault. Ici, nous donnons un droit administrateur sur EC2 et RDS qui peut être réduit au besoin.
Enfin, pour tester nos credentials, nous devons exécuter la commande Vault suivante, qui devrait nous retourner nos credentials de session AWS :
# Vault admin privilege (only for test)
$ vault write aws/sts/web-aws ttl=1m
Configurer une authentification pour notre pipeline Gitlab-CI avec Vault
Comment authentifier un job Gitlab-CI ?
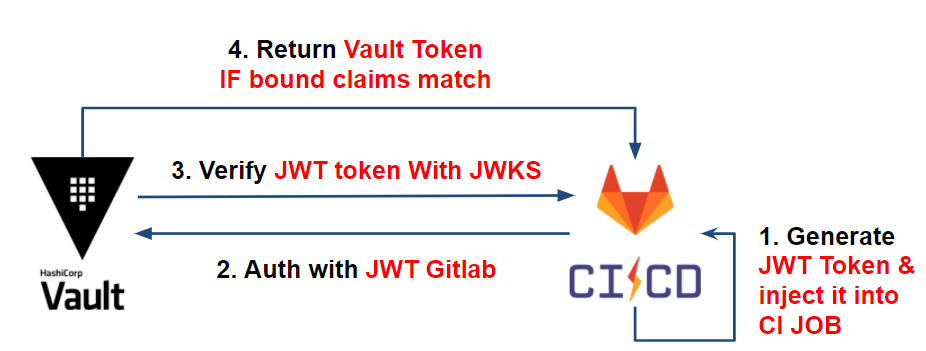
Chaque JOB dans Gitlab-ci possède un JWT (JSON Web Token) token accessible via la variable d’environnement CI_JOB_JWT.
Ce token JWT contient des informations (bound claims) en lien avec notre JOB de projet Gitlab-CI (project ID, issuer, la branche, etc) sur lequel Vault pourra se baser pour identifier notre pipeline. Celui-ci est encodé en RS256 et signé par une clé privée gérée par l’issuer: Gitlab-CI.
Comment cela fonctionne avec Vault ?
Pour vérifier l’authenticité des informations du token JWT, Vault va s’appuyer sur le JSON Web Key Sets (JWKS) de l’issuer contenant l’ensemble des clés publiques servant à signer les JWT.
Une fois l’authenticité du token prouvé, Vault va vérifier les informations du JWT (bound claims) et comparer celles-ci avec les informations attendues (que nous configurons plus bas), telles que: le project ID, l’issuer, la branche ciblé, etc.
Une fois que les informations du token correspondent aux attentes de Vault, celui-ci délivre son token avec la bonne policy à la CI permettant ainsi la récupération de ses secrets.
Ce qui nous donne le workflow suivant :
Pour plus d’informations, vous pouvez consulter les articles suivants :
- Gestion externe des secrets CI
- Authentifier sa CI et lire ses secrets avec HashiCorp Vault via Gitlab-CI
Mise en pratique avec Vault
Nous avons vu l’authentification JWT entre Vault et Gitlab-CI. Maintenant, penchons-nous sur la configuration côté Vault.
Pour notre cas d’usage, nous avons le schéma suivant :
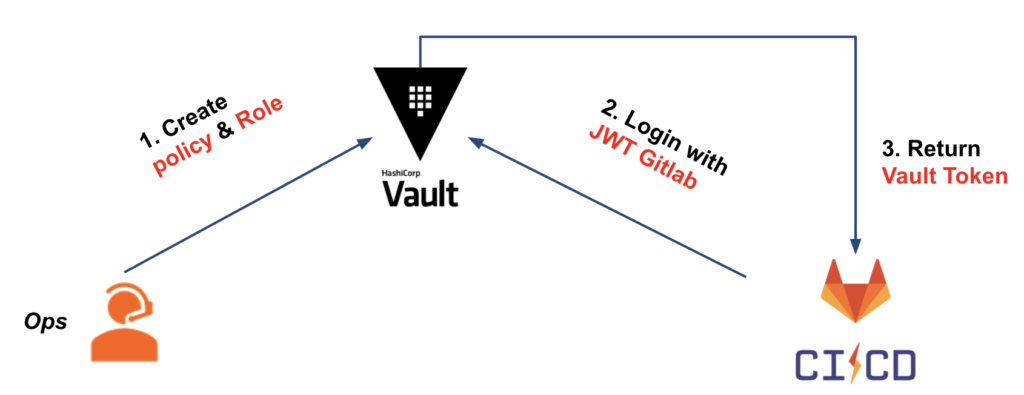
Pour pouvoir configurer notre Vault, nous allons créer :
- L’authentification de type JWT
- Le rôle Vault se basant sur l’authentification JWT sur lequel nous allons vérifier que les bound claims respectent nos critères
- La policy Vault attachée au token Vault, qui sera délivrée à notre CI et donnant notamment les droits nécessaires de récupérer les secrets (de type AWS ici)
Concernant nos deux premiers points, nous avons la configuration Terraform suivante :
resource "vault_jwt_auth_backend" "gitlab" {
description = "JWT auth backend for Gitlab-CI pipeline"
path = "jwt"
jwks_url = "https://${var.gitlab_domain}/-/jwks"
bound_issuer = var.gitlab_domain
default_role = "default"
}
resource "vault_jwt_auth_backend_role" "pipeline" {
backend = vault_jwt_auth_backend.gitlab.path
role_type = "jwt"
role_name = "${var.project_name}-pipeline"
token_policies = ["default", vault_policy.pipeline.name]
bound_claims = {
project_id = var.gitlab_project_id
ref = var.gitlab_project_branch
ref_type = "branch"
}
user_claim = "user_email"
token_explicit_max_ttl = var.jwt_token_max_ttl
}
Du côté de la configuration de notre JWT auth backend, celle-ci reste assez standard et demande de connaître le nom de domaine de notre Gitlab (ex: gitlab.com).
Du côté du JWT auth backend rôle, nous avons les bound_claims qui sont les critères à respecter pour autoriser l’authentification de notre CI, tels que:
- project_id: le numéro du projet Gitlab. Probablement l’élément le plus déterminant afin de n’autoriser que notre projet a s’authentifier.
- ref: dans notre cas, la branche sur lequel la CI s’exécute. Ici, nous prendrons master.
- ref_type: le type de la référence. Dans notre cas, nos références seront les branches GIT.
Enfin concernant la policy attribuée à notre rôle Vault, nous avons 4 path permettant à notre pipeline de :
- aws/sts/pipeline : récupérer ses secrets de type AWS.
- db/* : stocker les secrets de base de données à destination de notre projet.
- auth/aws/* : d’autoriser le projet a s’authentifier à Vault via une méthode d’authentification AWS. Nous verrons cette partie au niveau application.
- auth/token/create : de créer des tokens Vault enfant. En effet, Terraform, au travers du provider Vault, génère un token enfant avec un TTL court. Pour ce faire, nous devons attribuer ce chemin avec la capabilities « Update » afin d’autoriser Terraform à effectuer cette action. Cette subtilité est propre à Terraform et vous trouverez dans la documentation les informations complémentaires sur le sujet.
A ce stade, nous sommes en capacité d’authentifier et donner accès a notre CI avec Vault.
Utiliser nos secrets dans notre CI
Maintenant qu’il est possible à notre CI d’interagir avec Vault, penchons nous sur l’exécution de notre CI.
Voici le workflow que nous aurons à l’exécution de notre CI :
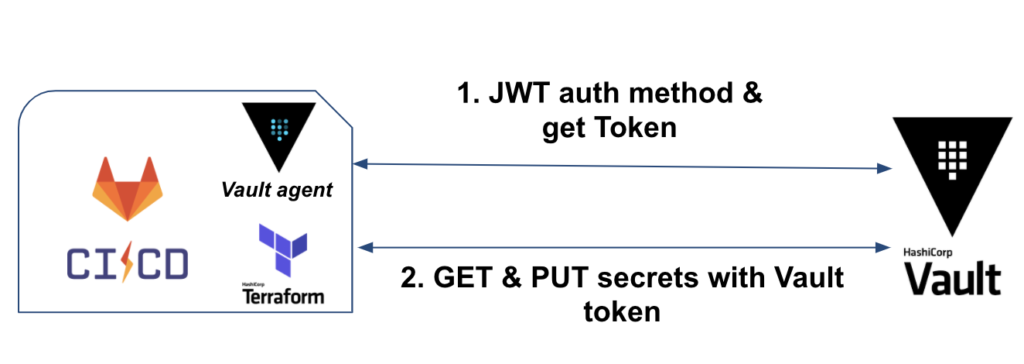
Dans un premier temps, nous aurons Vault binaire (ou Vault en mode agent) qui prendra en charge l’authentification et la récupération du token Vault.
Dans un second temps, Terraform sera utilisé pour récupérer les credentials AWS, déployer l’IaC et stocker les secrets de base de données.
Authentification d’un job CI via Vault
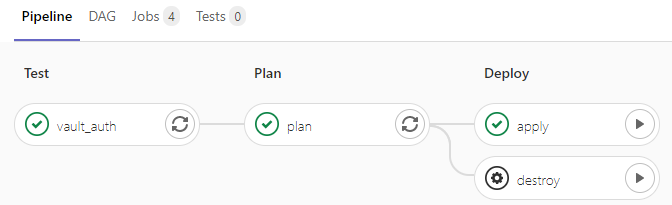
Concernant nos jobs CI, nous allons configurer notre gitlab-ci.yml, de façon à :
- Installer Vault et Terraform dans un before_script afin que les outils soient disponibles sur l’ensemble de nos jobs. Pour gagner du temps, vous pouvez construire votre propre image CI pour éviter de les installer à chaque démarrage de job.
- Avoir un premier job de test pour l’authentification JWT via Vault
- Une fois l’authentification testée et fonctionnelle, avoir 2 jobs séquentiels : terraform plan & terraform apply/destroy
Concernant notre job de test, nous avons l’extrait suivant :
image: bash
variables:
TF_VAR_vault_role: web-pipeline
TF_VAR_vault_backend: web-aws
vault_auth:
stage: test
script:
- export VAULT_TOKEN="$(vault write -field=token auth/jwt/login role=$TF_VAR_vault_role jwt=$CI_JOB_JWT)"
- vault token lookup
Concernant notre job vault_auth nous exécutons 2 commandes au niveau script:
- La première permet de s’authentifier à Vault via la méthode JWT.
- Nous précisons le rôle que nous souhaitons utiliser. Ici, le rôle est web-pipeline que nous avons configuré précédemment.
- Nous utilisons la variable d’environnement CI_JOB_JWT fournie par Gitlab-CI pour notre job. Cette variable contient le token JWT permettant d’authentifier notre job CI auprès de Vault.
- Enfin, nous récupérons le token Vault que nous mettons en variable d’environnement VAULT_TOKEN. Celui-ci sera utilisé de nouveau par Terraform pour la suite de ses actions.
- La seconde ligne
vault token lookuppermet de vérifier la durée de notre token Vault, les policies attachées, etc.
Usage des secrets via Terraform
Nous avons deux types de secrets sur lesquels Terraform, au niveau de notre CI, doit interagir :
- AWS : récupération des credentials de la session AWS via un assume rôle afin de déployer l’IaC. Dans notre cas : une instance EC2 et une base de données RDS.
- Database : stockage du secret de base de données au niveau de Vault. Dans notre cas : l’utilisateur administrateur de la base de données.
Pour les secrets AWS, Terraform est en capacité via le provider Vault de récupérer ses credentials :
data "vault_aws_access_credentials" "creds" {
backend = "aws"
role = "web-pipeline"
type = "sts"
}
provider "aws" {
region = var.region
access_key = data.vault_aws_access_credentials.creds.access_key
secret_key = data.vault_aws_access_credentials.creds.secret_key
token = data.vault_aws_access_credentials.creds.security_token
}
Concernant les secrets de base de données, une fois la RDS créée, nous établissons la connection entre Vault et celle-ci, permettant à Vault de faire ses actions sur la base de données au travers de l’utilisateur de base de données admin :
resource "vault_database_secret_backend_connection" "mysql" {
backend = local.db_backend
name = "mysql"
allowed_roles = [var.project_name]
mysql {
connection_url = "${aws_db_instance.web.username}:${random_password.password.result}@tcp(${aws_db_instance.web.endpoint})/"
}
}
Si vous souhaitez faire une rotation du mot de passe de l’administrateur afin de garantir que seul Vault soit sachant, vous pouvez effectuer la commande suivante :
# Vault admin privilege (only for test)
$ vault write -force web-db/rotate-root/mysql
Et enfin, pour que l’application puisse utiliser ses secrets de base données, nous créons un rôle Vault sur lequel celui-ci ira créer un utilisateur en readonly sur la base de données avec une durée définie (de préférence courte) :
# Create a role for readonly user in database
resource "vault_database_secret_backend_role" "role" {
backend = local.db_backend
name = web
db_name = vault_database_secret_backend_connection.mysql.name
creation_statements = ["CREATE USER '{{name}}'@'%' IDENTIFIED BY '{{password}}';GRANT SELECT ON *.* TO '{{name}}'@'%';"]
default_ttl = var.db_secret_ttl
}
Nous pouvons tester, une fois le projet déployé au travers de la CI, nos secrets applicatifs de cette façon :
# Vault admin privilege (only for test)
$ vault read web-db/creds/web ttl=1m
Arrivé à ce stade, nous avons réussi à répondre à nos différentes problématiques pour notre CI. Ce qui donne le résultat suivant :
L’expiration et la rotation de nos secrets CI
Jusqu’à maintenant, nous avons réussi à mettre en place une CI au travers de Gitlab, Terraform et Vault qui répond à nos différentes problématiques.
Ce qui donne le workflow suivant :
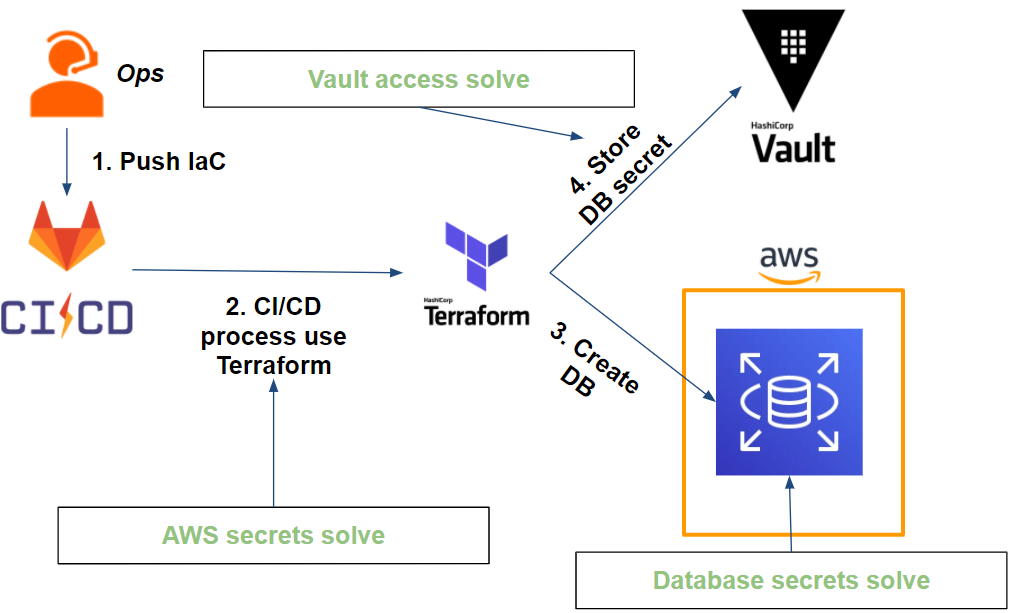
Si l’accès de à nos secrets est sécurisé, qu’en est-il de la rotation ?
- L’accès au Vault qui se fait via le token Vault : le Vault CLI s’occupe de s’authentifier à chaque lancement de job Gitlab-CI. Autrement dit, le token Vault est unique par job (token jetable) et a un TTL limité dans le temps (ex: 1min).
- Les secrets AWS : Terraform récupère les secrets AWS (session assumée au travers d’un rôle Vault) à chaque exécution. Les secrets sont uniques à chaque exécution et limités dans le temps (ex: 5min).
- Les secrets de base de données sont à 2 niveaux :
- L’utilisateur de base de données administrateur est stocké dans Vault et son mot de passe est changé par Vault. A ce stade seul Vault est en capacité de connaître les credentials (en excluant les administrateurs Vault)
- L’utilisateur de base de données applicative est généré à la demande de l’application et a un TTL limité dans le temps (ex: 1 heure). Le secret en question est un utilisateur en readonly et donc en droit limité.
Nous avons vu comment résoudre nos problématiques niveau CI mais celle-ci ne s’arrête pas qu’au déploiement de l’infrastructure de notre application.
En effet, il reste à notre application à récupérer ses secrets au travers de Vault. Comment pouvons-nous répondre à cette problématique de façon la plus transparente possible ?
HashiCorp Gitlab Terraform Gitlab-CI Vault CI/CD AWS Amazon Web Services Runner Jobs JWT Authentication method Least privileges Vault Agent Terraform provider Secret as a Service Application Database Pipeline
3594 Mots
2021-03-01 16:30